Amundsen Data Catalog
Amundsen Data Catalog - In addition to “real use” the. Learn the technical differences between amundsen and datahub for data cataloging and metadata management. Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists and engineers when interacting with data. Amundsen is an open source project that helps data analysts, scientists and engineers find and understand data resources. It does that today by. It indexes data sources, provides se… Amundsen is a data tool designed to streamline the process of elt (extract, load, transform) by providing a comprehensive data catalog. By providing a central portal and search for your data assets, it. Amundsen helps you find and trust data within your organization by a simple text search. In this article, we will address key questions related. Amundsen provides a data ingestion library for building the metadata. Amundsen helps you find and trust data within your organization by a simple text search. By providing a central portal and search for your data assets, it. It provides automated and curated metadata, easy triage, and learning from others for data. Learn the technical differences between amundsen and datahub for data cataloging and metadata management. Learn how to use amundsen, a data catalog for data management and discovery, with features, benefits, deployment strategies, and future enhancements. The cluster is deployed in our private subnets, and uses the security groups created by our vpc stack. Our goal is to build a representative dataset to catalog with our amundsen databuilder. Amundsen, let's explore the key differences in the architecture, data discovery features, data source integrations, and data governance capabilities of the two popular open. In this post, we discuss amundsen’s architecture in depth, explain how this tool democratizes data discovery, and cover some challenges we faced when designing the product. Amundsen helps you find and trust data within your organization by a simple text search. In this post, we discuss amundsen’s architecture in depth, explain how this tool democratizes data discovery, and cover some challenges we faced when designing the product. At lyft, we build the metadata once a day using an airflow dag (examples). In this article, we will. In this post, we discuss amundsen’s architecture in depth, explain how this tool democratizes data discovery, and cover some challenges we faced when designing the product. In this article, we will address key questions related. It does that today by. Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists and engineers when. It provides automated and curated metadata, easy triage, and learning from others for data. By providing a central portal and search for your data assets, it. In this post, we discuss amundsen’s architecture in depth, explain how this tool democratizes data discovery, and cover some challenges we faced when designing the product. Learn the technical differences between amundsen and datahub. It does that today by. The cluster is deployed in our private subnets, and uses the security groups created by our vpc stack. Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data. Amundsen, let's explore the key differences in the architecture, data discovery features, data source integrations, and. By providing a central portal and search for your data assets, it. It indexes data sources, provides se… Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data. The cluster is deployed in our private subnets, and uses the security groups created by our vpc stack. At lyft, we. Amundsen helps you find and trust data within your organization by a simple text search. At lyft, we build the metadata once a day using an airflow dag (examples). Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists and engineers when interacting with data. Compare their search capabilities, metadata management, data. Learn. Amundsen is a data tool designed to streamline the process of elt (extract, load, transform) by providing a comprehensive data catalog. Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data. Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists and. Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data. Amundsen helps you find and trust data within your organization by a simple text search. Amundsen, let's explore the key differences in the architecture, data discovery features, data source integrations, and data governance capabilities of the two popular open.. At lyft, we build the metadata once a day using an airflow dag (examples). Our goal is to build a representative dataset to catalog with our amundsen databuilder. Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data. Amundsen provides a data ingestion library for building the metadata. Amundsen,. Amundsen is an open source project that helps data analysts, scientists and engineers find and understand data resources. In addition to “real use” the. Amundsen is a data tool designed to streamline the process of elt (extract, load, transform) by providing a comprehensive data catalog. Learn the technical differences between amundsen and datahub for data cataloging and metadata management. Amundsen,. Amundsen, let's explore the key differences in the architecture, data discovery features, data source integrations, and data governance capabilities of the two popular open. Amundsen is an open source project that helps data analysts, scientists and engineers find and understand data resources. Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data. Amundsen provides a data ingestion library for building the metadata. Amundsen is a data tool designed to streamline the process of elt (extract, load, transform) by providing a comprehensive data catalog. Our goal is to build a representative dataset to catalog with our amundsen databuilder. Amundsen helps you find and trust data within your organization by a simple text search. The cluster is deployed in our private subnets, and uses the security groups created by our vpc stack. In this article, we will address key questions related. In this post, we discuss amundsen’s architecture in depth, explain how this tool democratizes data discovery, and cover some challenges we faced when designing the product. It provides automated and curated metadata, easy triage, and learning from others for data. It indexes data sources, provides se… It does that today by. Learn the technical differences between amundsen and datahub for data cataloging and metadata management. Learn how to use amundsen, a data catalog for data management and discovery, with features, benefits, deployment strategies, and future enhancements. Compare their search capabilities, metadata management, data.
Ferramentas de Catalogação de Dados Opensource Data Heroes
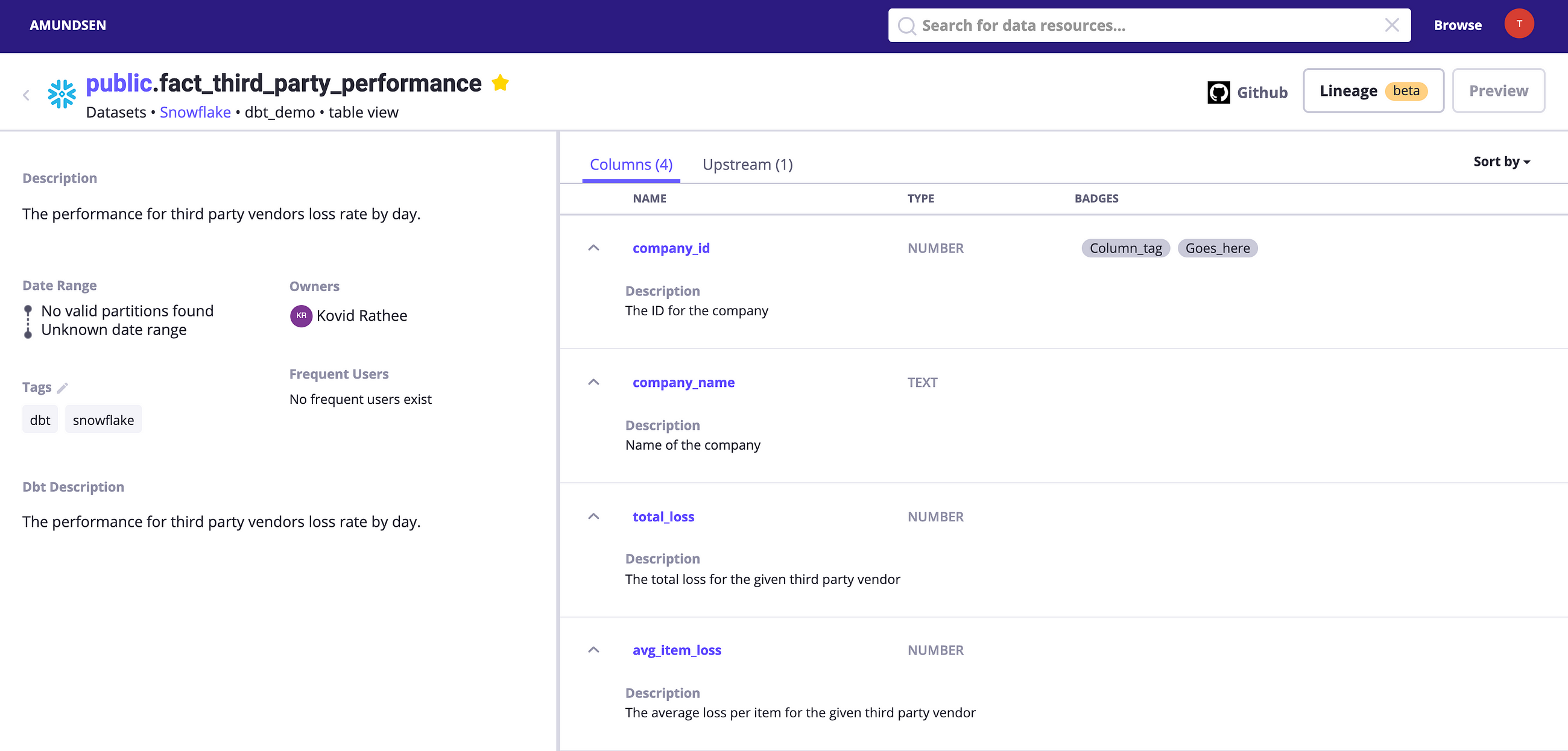
How to Set Up Amundsen Data Lineage Using dbt

Amundsen Data Catalog Features, Setup, Uses & Alternatives

The Evolution of the Amundsen Data Catalog Features, Setup, and Benefits

LF AI & Data Foundation Logos and Artwork Amundsen
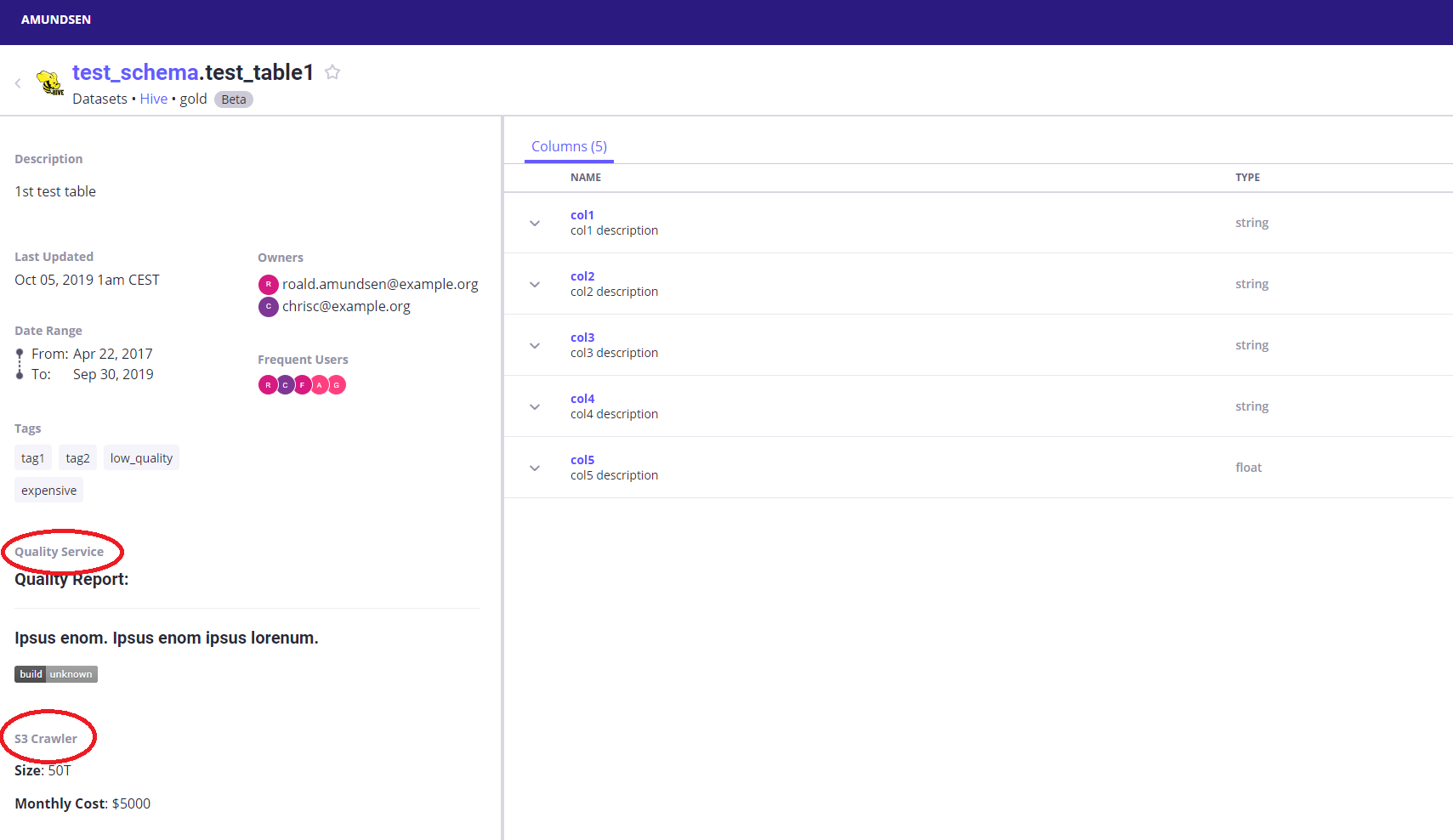
Testing Open Source Data Catalogs Syntio
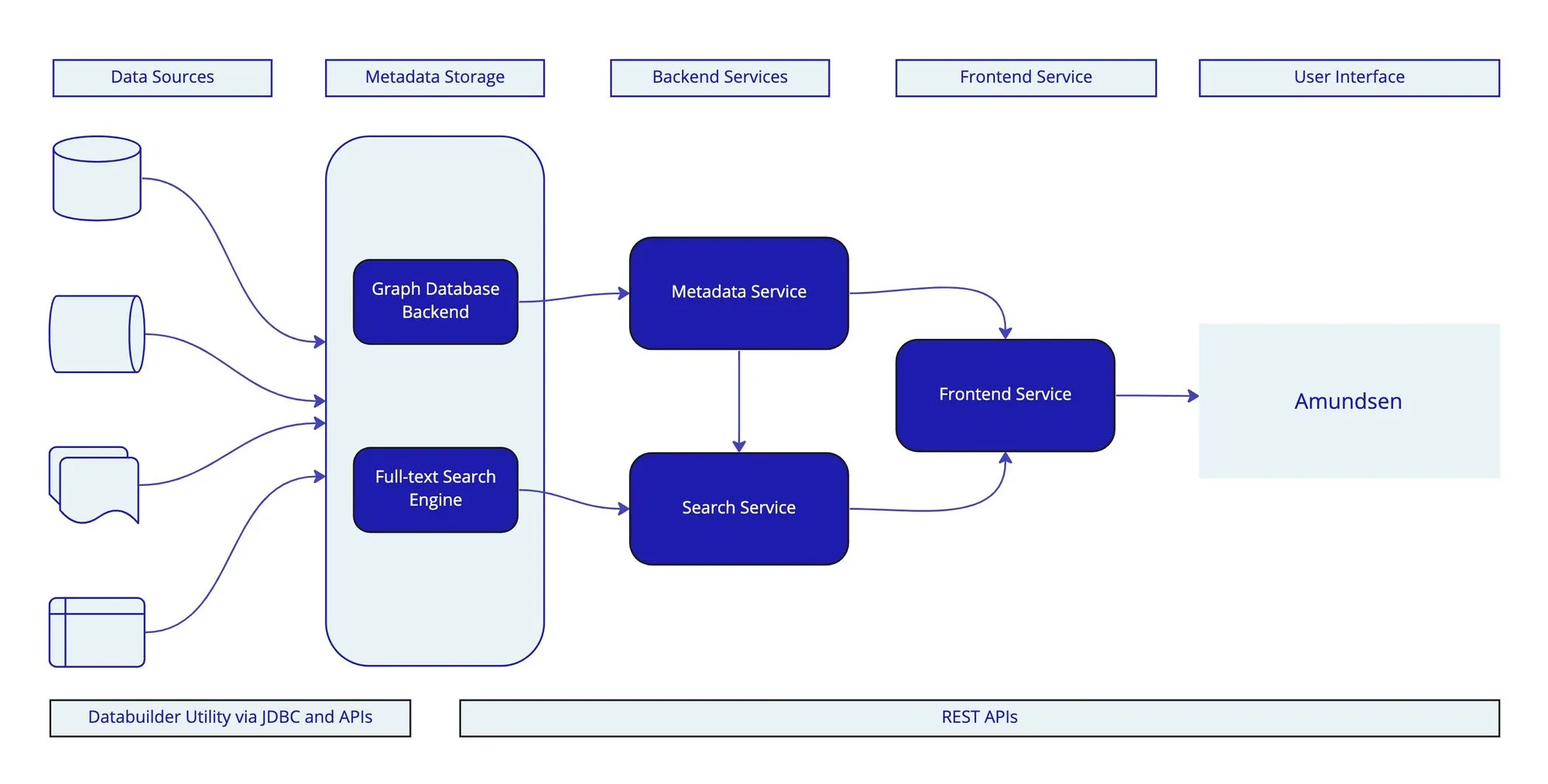
Amundsen Data Catalog Features, Setup, Uses & Alternatives
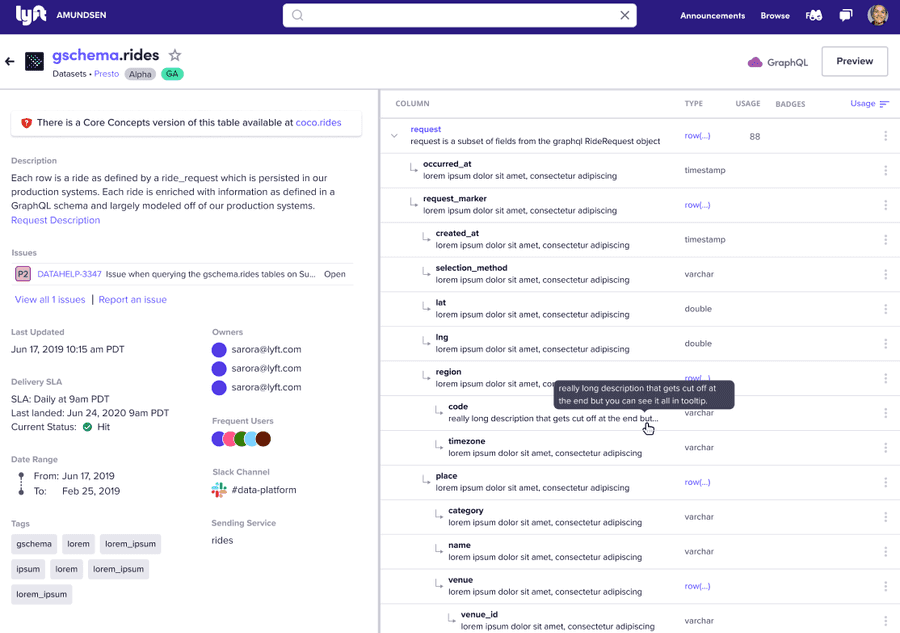
Amundsen Data Catalog Tool Marcos Iglesias' Personal Site

Amundsen Data Catalog Features, Setup, Uses & Alternatives
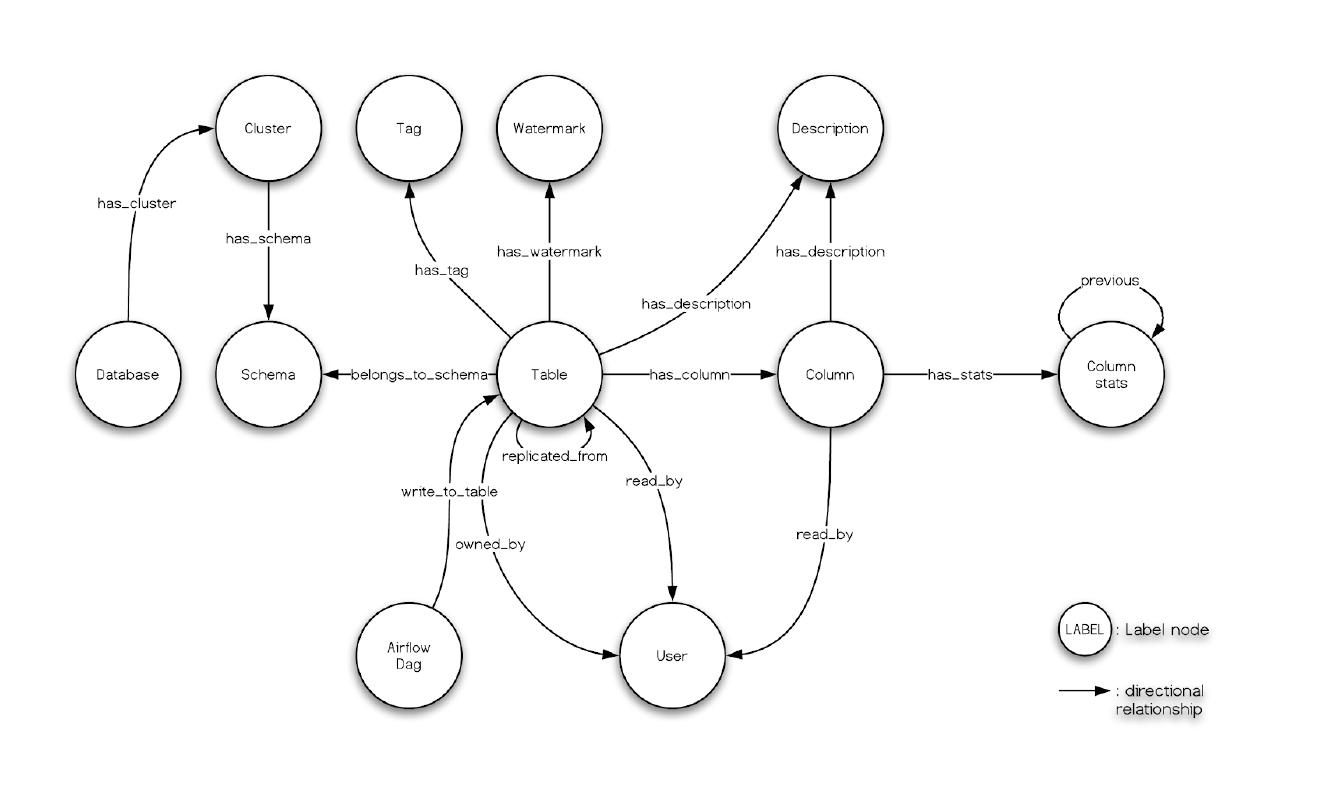
Trino 26 Trino discovers data catalogs with Amundsen
Amundsen Is A Data Discovery And Metadata Engine For Improving The Productivity Of Data Analysts, Data Scientists And Engineers When Interacting With Data.
In Addition To “Real Use” The.
At Lyft, We Build The Metadata Once A Day Using An Airflow Dag (Examples).
By Providing A Central Portal And Search For Your Data Assets, It.
Related Post: